
社内データを賢く探す仕組み|LangChain×Pineconeで実現する高精度なAI検索
フィリピンで日系企業のAI導入を支援する立場から、LangChainとPineconeを使った高精度な社内AI検索の仕組みを解説。テクノロジーの専門用語をかみくだき、導入手順や注意点までわかりやすく紹介します。

運営者・AIエンジニア / IT歴36年以上・マニラ在住13年以上

社内データを賢く探す仕組み|LangChain×Pineconeで実現する高精度なAI検索
社内には、マニュアルや議事録、過去のメールなど膨大な情報が眠っています。しかし「あの資料、どこにあったかな」と探すだけで何分も、ときには何十分も使ってしまうことはないでしょうか。
この記事では、社内データをAIが正しく理解して、欲しい答えをすぐに見つけてくれる仕組みを解説します。フィリピンで日系企業のAI導入を支援してきた経験をもとに、専門用語をかみくだいて紹介しますので、最後まで読めば自社で何から始めればよいかが見えてきます。
要約
- 普通の検索は文字の一致しか見ないため、「有給」と「休暇」のように言い回しが違うと、社内に答えがあっても見つけられません。
- LangChainとPineconeを組み合わせると、言葉の意味で探すAI検索ができ、表現のズレに関係なく欲しい情報にたどり着けます。
- 導入は準備・変換・保存・検索の4ステップで進み、FAQやマニュアルなど一部のデータから小さく始めると失敗しにくくなります。
「検索したのに欲しい答えが出てこない」という悩み
| 課題 | 起きていること |
|---|---|
| キーワードが一致しない | 言葉が少しズレると検索に引っかからない |
| 人に聞くしかない | 社内に答えがあるのに見つけられない |
| 同じ質問の繰り返し | 社員の時間が奪われ生産性が下がる |
多くの会社では、ファイル名やキーワードで社内データを探しています。しかしこの方法だと、言葉が少しでもズレると検索に引っかからないという問題が起きます。
 必要な資料がすぐに見つからず、探すだけで時間を取られてしまう様子
必要な資料がすぐに見つからず、探すだけで時間を取られてしまう様子
たとえば「有給の申請方法」を知りたいのに、資料には「休暇取得フロー」と書かれていると、キーワードが一致せず見つかりません。結果として、本当は社内に答えがあるのに「誰かに聞く」しか方法がなくなってしまいます。
こうした状況は、社員の時間を奪うだけでなく、同じ質問が何度も繰り返される原因にもなります。情報がうまく探せないことは、会社全体の生産性を静かに下げているのです。
私も2000年代に日本でSEOやアフィリエイトの事業をしていた頃、手作業でメールに返信したり、FAQページを案内したりして顧客対応をしていました。とくに「なぜ上位に出ないのか」という似たような質問が何度も寄せられ、その対応に時間を取られていたことを今でもよく覚えています。
関連: LangChainとPineconeとは?自社専用AIを支える「司令塔」と「記憶庫」の役割を解説 で詳しく解説しています。
なぜ普通の検索では情報が見つからないのか
| 原因 | 内容 |
|---|---|
| 文字一致だけの検索 | 言葉の意味ではなく見た目の一致を探している |
| 同義語が分からない | 「有給」と「休暇」を別の言葉として扱う |
| データが散らばっている | 形式も置き場所もバラバラで意味でつながっていない |
従来の検索は、入力した言葉と資料の中の言葉が「文字として一致するか」だけを見ています。つまり言葉の意味ではなく、見た目の一致を探しているのです。
人間は「有給」と「休暇」がほぼ同じ意味だと分かりますが、ただの文字一致の検索にはそれが分かりません。そのため、表現が違うだけで答えにたどり着けなくなります。
さらに、社内データはWordやPDF、メールなど形式がバラバラで、置き場所も部署ごとに分かれていることが多いです。情報が散らばっていて意味でつながっていないことが、検索を難しくしている根本の原因です。
意味で探すAI検索という解決策
| 道具 | 役割 |
|---|---|
| ベクトル検索 | 文章の意味を数値にして近い意味どうしを結びつける |
| LangChain | AIと社内データをつなぐ司令塔 |
| Pinecone | 意味を数値にした情報を保存する専用の倉庫 |
この問題を解決するのが、言葉の意味で探すAI検索(ベクトル検索)という考え方です。文字の一致ではなく、文章の意味を数値に変換して、近い意味どうしを結びつけます。
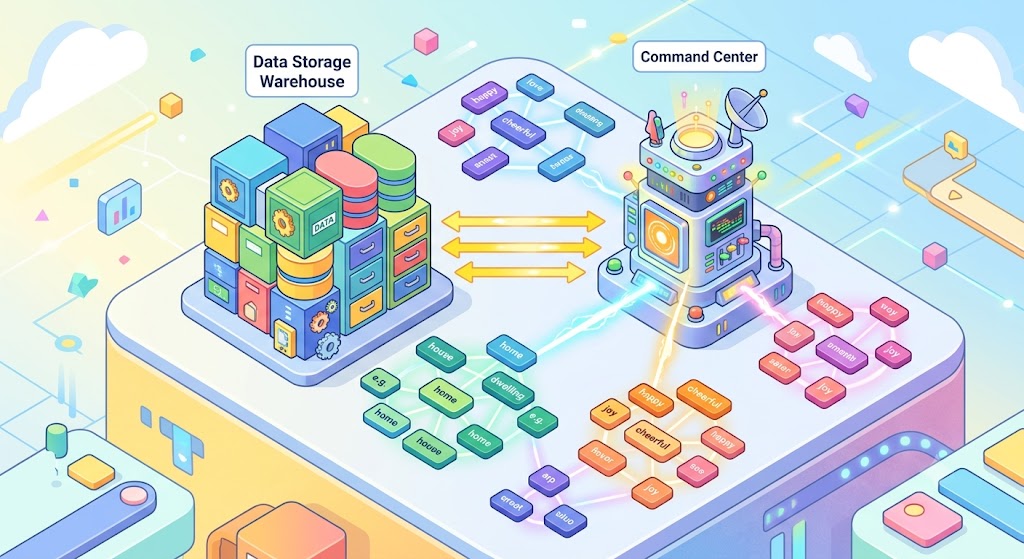 文字の一致ではなく意味でつなぐベクトル検索のイメージ
文字の一致ではなく意味でつなぐベクトル検索のイメージ
ここで活躍するのがLangChainとPineconeという2つの道具です。LangChainはAIと社内データをつなぐ「司令塔」、Pineconeは意味を数値にした情報を保存する「専用の倉庫」だと考えると分かりやすいです。
この仕組みを使うと、「有給の申請方法」と質問したときに、「休暇取得フロー」の資料も意味が近いものとして自動的に見つけてくれます。言い回しの違いを気にせず、知りたいことにそのまま答えてくれるようになります。
実際に私がマカティのリトルトーキョー近くにある日系の飲食店でAI導入を支援したときも、サイトにAIチャットボットを入れて、単純な問い合わせはAIに任せる仕組みを作りました。その結果、単純な質問を人が対応することはほぼなくなり、スタッフの負担を大きく減らせました。社内データの検索でも、これと同じように「人に聞かなくてもAIが答えてくれる」状態を目指せます。
関連: 専用ベクトルDBとは?非エンジニアでもわかるAIの仕組みをやさしく解説 で詳しく解説しています。
LangChain×Pineconeで検索を作る手順
| ステップ | 内容 |
|---|---|
| 準備 | 社内データを集めて適度な長さに区切る(チャンク分割) |
| 変換 | 区切った文章を意味を表す数値(ベクトル)に変える |
| 保存 | 変換した数値をPineconeに登録する |
| 検索 | 質問を数値にして意味の近いデータを探し答えを返す |
実際の流れは、大きく4つのステップに分けられます。準備・変換・保存・検索の順に進めると理解しやすいです。
 社内データをAI検索にする4つのステップの流れ
社内データをAI検索にする4つのステップの流れ
まず準備として、社内のマニュアルやFAQなどを集め、長い文章は適度な長さに区切ります。区切る作業は「チャンク分割」と呼ばれ、情報を探しやすい大きさに整えるための大切な工程です。
次に変換のステップでは、区切った文章をAIが「意味を表す数値(ベクトル)」に変換します。たとえば「休暇」と「有給」は数値の上でも近い位置に置かれ、意味の近さが数字で表現されるようになります。
そして保存のステップで、その数値をPineconeに登録します。最後の検索のステップでは、利用者の質問も同じように数値へ変換し、Pineconeの中から意味が近いデータを探し出してLangChainが答えとして返します。
関連: RAG時代の終焉とエージェント型AI基盤 — フィリピン拠点で活きる知識コンパイル層の実務 で詳しく解説しています。
つまずきやすいポイントと失敗例
| つまずき | 対策 |
|---|---|
| 区切る大きさが不適切 | 大きすぎ・小さすぎを避け、適切な長さに整える |
| 元データの質が低い | 古い・間違った資料は登録前に見直す |
| 機密情報の扱い | 登録する情報と除く情報を最初に決める |
最初の失敗で多いのが、文章を区切る大きさを適当に決めてしまうことです。区切りが大きすぎると余計な情報まで含まれ、小さすぎると意味が途切れて、どちらも検索の精度が下がります。
次に注意したいのが、元になる社内データの質です。古い情報や間違った資料をそのまま登録すると、AIも間違った答えを返します。登録する前に内容を見直し、不要な資料を整理しておくことが欠かせません。
また、機密情報の扱いにも気をつける必要があります。給与や個人情報などをそのまま登録すると情報漏えいのリスクがあるため、何を登録して何を除くかを最初に決めておくことが重要です。導入後も定期的にデータを更新し、最新の状態を保つことを忘れないようにしましょう。
よく来る質問
Q: プログラミングの知識がなくても導入できますか
A: 仕組みを作る部分には開発の知識が必要ですが、完成したあとは普通の検索のように使えます。社内に担当者がいない場合は、外部の支援を受けて初期構築だけ任せる方法が現実的です。
Q: 費用はどのくらいかかりますか
A: Pineconeは保存するデータ量や利用回数に応じた料金で、小規模なら月数十ドル程度から始められることが多いです。データ量や利用人数が増えると費用も上がるため、まずは一部の部署で試すのがおすすめです。
Q: ChatGPTにそのまま聞くのと何が違いますか
A: 一般的なAIは社内の事情を知らないため、自社専用の答えは返せません。この仕組みは自社のデータをもとに答えるので、社内ルールや独自の情報にもとづいた回答が得られます。
Q: どんなデータから始めるのがよいですか
A: まずは質問が集中しやすいFAQや業務マニュアルから始めると効果を感じやすいです。よく聞かれる内容を先に登録することで、問い合わせ対応の負担をすぐに減らせます。
まとめ
社内データが探せない原因は、従来の検索が「文字の一致」しか見ていないことにありました。LangChainとPineconeを使えば、言葉の意味で探す高精度なAI検索が実現でき、言い回しの違いに左右されずに答えが見つかります。
導入の第一歩としては、いきなり全社に広げるのではなく、FAQやマニュアルなど一部のデータから小さく試すことをおすすめします。まずは自社にどんなデータが眠っているかを洗い出し、整理することから始めてみてください。
私自身、IT・Web・AIに36年以上携わってきた経験から、こうした仕組みは段階的に導入して少しずつ改善していくのが成功の近道だと感じています。最初から完璧を目指さず、まずは70%ほどの状態で使い始めて、実際に使ったデータをもとに直していくと、無理なく定着していきます。
参考・出典
- LangChain 公式サイト: https://www.langchain.com/
- Pinecone 公式サイト: https://www.pinecone.io/
この記事を書いた人
運営者 / AIエンジニア(IT歴36年以上)
- ●東京都出身・マニラ在住13年以上
- ●IT歴36年以上(開発・SEO・AI)
- ●IBM認定 生成AIエンジニア
- ●AIチャットボット・RAG・AIエージェント開発
IT歴36年以上、マニラでの実務経験13年以上の日本人AIエンジニア(運営者)です。AIチャットボットや業務自動化、AIエージェント、生成AIマーケティングなど、フィリピンの日系企業が「成果に直結するAI」を導入できるよう、現場目線で記事を書いています。ご相談は日本語・英語どちらでも対応します。
関連記事

フィリピンのサリサリストアでもAIは使える?小さな個人商店の活用術
フィリピンのサリサリストアでもAIは使えます。スマホの無料AIアプリで在庫管理や仕入れ相談、問い合わせ返信を自動化する方法を、テクノロジー導入の視点から高校生にもわかる言葉で紹介します。
2026/6/20

AIのファインチューニングはどう変わる?LoRAとQLoRAの違いをやさしく解説
フィリピンの日系企業向けに、AIのファインチューニング手法LoRAとQLoRAの違いをやさしく解説。メモリやコストに応じた選び方、よくある失敗、最新テクノロジーを業務に活かす進め方を具体的に紹介します。
2026/6/11

LangChainとPineconeとは?自社専用AIを支える「司令塔」と「記憶庫」の役割を解説
自社専用AIを支えるLangChainとPineconeの役割を、司令塔と記憶庫のたとえでやさしく解説。フィリピン在住のAIエンジニアが、最新テクノロジーを使った導入の流れや注意点を紹介します。
2026/6/8

非エンジニア向けAI「省エネ学習」PEFTとは?低コストで自社向けAIを育てる方法
AIの「省エネ学習」PEFTを非エンジニア向けにやさしく解説。少ないコストと手間で自社向けAIを育てるしくみや手順、失敗を避けるコツを紹介します。フィリピンの日系企業のAI・テクノロジー導入にも役立つ内容です。
2026/6/8

専用ベクトルDBとは?非エンジニアでもわかるAIの仕組みをやさしく解説
フィリピン在住の日本人AIエンジニアが、専用ベクトルDBの仕組みを非エンジニア向けに解説。AIに社内資料を答えさせるテクノロジーの基礎と、導入が必要になる判断基準をやさしく整理します。
2026/6/6

RAGとは?非エンジニアでもわかるAI連携の仕組み
フィリピンの日系企業向けにAIエンジニアが解説。RAGは自社資料を探してAIに渡し、正確な回答を引き出すテクノロジーです。導入手順や注意点、よくある失敗をわかりやすくまとめました。
2026/6/5